
Multi model with prompt in visual dialog
Daily ·组会+调研
更改链接:
Meeting of icat:
- lyc师兄:引入了对齐,图像和文字?双模态。多任务调点不一定能调回来。视频with音频。
- lh师兄: icassp的初稿展示。feedback:最大的图要有details,尽量形象化。可视化效果(可见的改进)。表格要和sota比较。尽量要放入年份(baseline不要选太老)。
- sd师兄:刷出sota但是不是全方面的。(模型压缩)参数量剪枝和运算量剪枝。
- yxy师兄,视频帧的筛选,预处理的方法。details被存到json里面。
-
lzy(me)的问题:没有预处理好数据(提前分好段,然后再处理),目前的数据为假数据。
- p-tuning
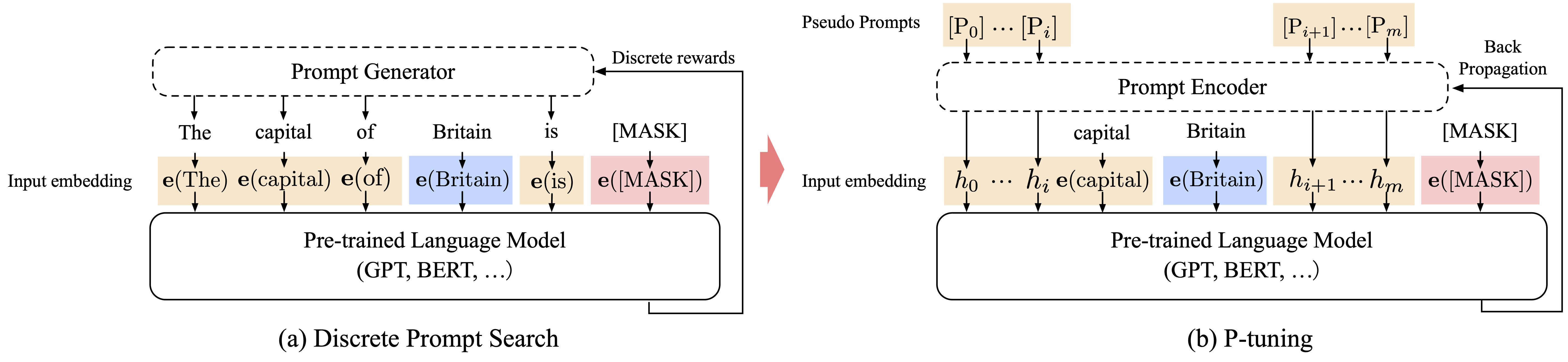
鹏飞老师报告: 依赖于外部知识接口 and 基于知识的。 大模型的fine tuning任务。 pt的直观概念,在搜索引擎搜索的时候,query the key word就会有提示出来。 coding的时候,vscode可以自动补齐。 prompt 基于知识,提升模型的预测能力。 存在模板:[x] 存在slot 留给预测的answer。 label -> 需要人工的建立。 预训练模型的选择。BART直接使用,不需要训练。 将label预测,将预测结果放回模板中形成x’ 最终x’就是prompt 模板的设计策略,最重要的是中文预训练语言模型的好坏。
p-tuning v2 :每层transformer都有。 GPT3 不适合fine-tune。 MegatronLM 无法直接fine-tune。会出现OOM。110亿。 命名实体识别(NER) hard to use prompt.抽取式的QA
## p-tuning的视频
Transformer编码器和解码器之间的区别: encoder对第i个元素抽取特征的时候,可以看到全部元素的信息。 decoder对第i个元素抽取特征的时候,只可以看到周围的信息。存在掩码
why gpt is a auto-regressive model? 使用自己的预训练任务再次训练。
最近两天的goals; 如何预处理visual dialog数据,查看visualdial的引用,寻找benchmarks。抄袭一下visualdial的导入流程。